Reliability without Validity: A Systematic, Large-Scale Evaluation of LLM-as-a-Judge Models Across Agreement, Consistency, and Bias
 Kappa deflation and the consistency-bias paradox in LLM-as-a-Judge evaluation
Kappa deflation and the consistency-bias paradox in LLM-as-a-Judge evaluationAbstract
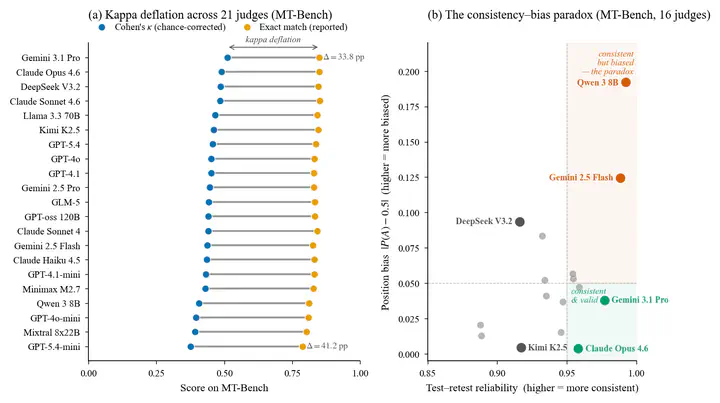
LLM-as-a-Judge has become the dominant evaluation paradigm for language models, yet judge validation in practice relies on exact-match agreement, a metric that does not correct for chance and systematically overstates discriminative ability. We present the largest systematic evaluation of LLM-as-a-Judge to date: 21 judges from nine providers across MT-Bench, JudgeBench, and RewardBench, evaluated under three protocols (agreement, consistency, bias audit) over 118 runs and approximately 541,000 individual judgments. Four findings emerge, consistent across the full cohort, including the April 2026 frontier: kappa deflation between exact match and Cohen’s kappa is universal (33-41 pp on MT-Bench), judge rankings shift by up to 14 positions across benchmarks, high test-retest reliability (>0.95) coexists with severe position bias (>0.10) in two production-deployed judges, instantiating a consistency-bias paradox, and verbosity bias is small (<0.011) across our cohort under a single pairwise rubric. We distill these into a Minimum Viable Validation Protocol.