Audio Deepfake Detection Using Temporal Coherence Analysis
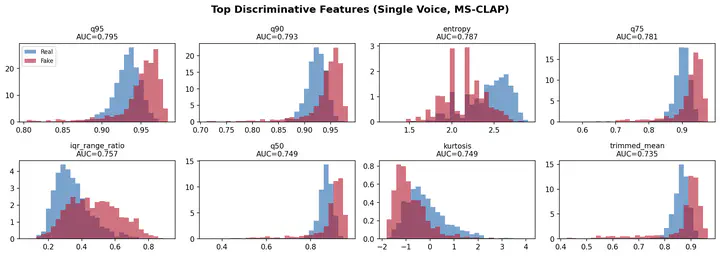 Top discriminative features for single voice deepfake detection using MS-CLAP embeddings
Top discriminative features for single voice deepfake detection using MS-CLAP embeddingsAbstract
The proliferation of AI-generated audio, so-called deepfake audio, poses significant threats to information integrity, from voice cloning fraud to synthetic music copyright disputes. We present a forensic approach to audio deepfake detection that analyzes temporal coherence anomalies in Contrastive Language-Audio Pretraining (CLAP) embeddings across a range of audio types; including speech, instrumental music, and music with vocals. By computing pairwise cosine similarities between audio segment embeddings and extracting statistical features from subsequently computed distributions, we train lightweight ensemble classifiers which are able to reliably distinguish authentic from synthetic audio. For speech deepfakes, this ensemble achieves F1 = 0.679 and AUC = 0.718 on completely unseen evaluation data, matching the performance of end-to-end neural approaches such as RawNet2, while utilizing computationally efficient, highly interpretable feature-based modeling. For music deepfakes, we achieve near-perfect in-distribution detection (F1 = 0.995) and introduce a domain-adaptive percentile classifier that retains this performance on out-of-distribution evaluation (SONICS/FMA), exceeding published cross-domain results. Our approach provides an interpretable, computationally expeditious alternative to common deep learning methods while still achieving competitive or state-of-the-art performance across speech and music domains.